The algorithm that search engines use have two main functions, to crawl and to index. Crawling is finding sites no matter what they are, while indexing sorts them into specific categories and keywords. However early engines were closer to a list as they could not crawl, or needed a human to crawl manually for them.
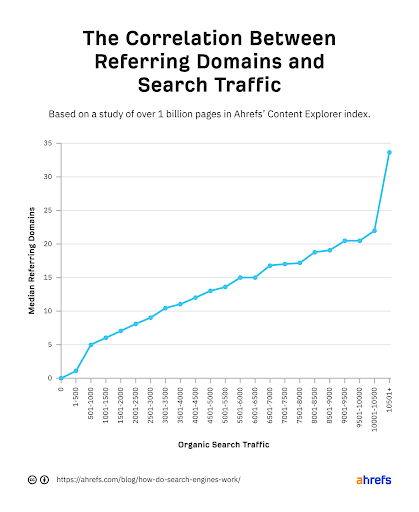
Most engines also have a second algorithm. This decides what is shown higher on a page. Most commonly the more times a website is cited and clicked on, the higher it is. The most popular of these algorithms is Page Rank, owned by Google.
Search engines also need a way to make money. They often have people pay them to feature their page at the top when people search for the related topic.

Ahrefs Blog, How Search Engines Work, September 1st, 2022, Joshua Hardwick, Patrick Stox, Sam Oh